A Byte Order Mark (BOM) can appear at the start of a file to indicate Unicode encoding, which version of Unicode (8, 16, 32) and the endedness (See Byte Order Mark). UTF-8 doesn't require a BOM (since endedness is not an issue for 8-bit encoding), but the presence of a BOM can interfere with code that's not expecting it. Here are some techniques for removing it.
What is a Byte Order Mark?
For Unicode, a BOM is a sequence of two, three or four characters embedded at the beginning of a file. For UTF-8 the sequence is always the three characters 0xEF, 0xBB, 0xBF. The presence of a BOM indicates that the subsequent data is Unicode data. The characters are chosen to be unique, and to appear in such a way as to indicate the byte order of encoding within the file. UTF-16 and UTF-32 require this information to decode 16- and 32-bit values correctly on differing systems, but UTF-8 is immune to endedness considerations, so this function of the BOM is redundant.
It is common for UTF-8 files not to have a BOM. So common, in fact, that the presence of a BOM can interfere with code that is not expecting it, even if the code will handle UTF-8 encoding in the body of the file.
JavaScript
JavaScript automatically reads and strips the BOM from files read as text with FileReader.readAsText(). This is true for current versions of Firefox, Chrome and Edge. UTF-8 characters will be correctly decode, whether or not a BOM is found. Note: if the file is read with FileReader.readAsBinaryString() the BOM is retained and UTF-8 characters are not decoded.
PHP
PHP makes no attempt to identify a BOM or remove it (tested in file_get_contents(), file(), and fopen()/fread()). Where PHP is handling text and it is possible that a BOM is present, your code should strip the BOM before processing the rest of file. Fortunately, this is easy to do:
$bom = hex2bin('EFBBBF');
$text = preg_replace("/^$bom/", '', $text);
Python
Like PHP, Python makes no attempt to deal with Byte Order Marks. This snippet copies <stdin> to <stdout>, stripping the BOM along the way. It's easy enough to take the key parts of this and incorporate them in a larger program.
import codecs
import shutil
import sys
s = sys.stdin.read(3)
if s != codecs.BOM_UTF8:
sys.stdout.write(s)
shutil.copyfileobj(sys.stdin, sys.stdout)Removing the BOM with an external tool
It is not always possible to modify code to remove the BOM as part of its normal processing. There are tools that can do this before you submit the file for processing:
Notepad++
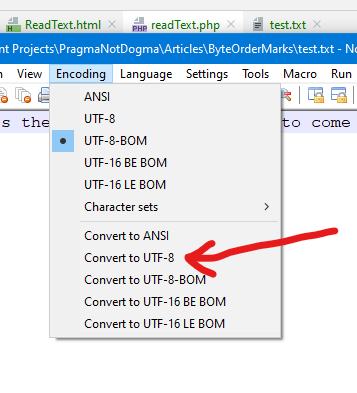
Notepad++ has a comprehensive set of conversion tools for different encodings listed in the Encoding menu. For limited use, and relatively small files, this could be a good option.
Open the text file, click Encoding and select the desired option from the list presented: Convert to UTF-8 should do. Save the file.
sed (for Linux users)
If you're using the bash shell you can use sed to remove the Byte Order Mark from the command line, and hence as part of a bash script.
sed -i $'1s/^\uFEFF//' file.txtvim - also for Linux users
vim <filename> "+set nobomb" "+wq"